

Untuk menjawab pertanyaan ini dari data yang kita miliki kita akan menambah satu variabel lagi yaitu umur kuadrat (hanya sebagai contoh saja). Dengan demikian, data tersebut menjadi sebagai berikut:

Langkah pertama seperti biasa adalah merumuskan hipotesis nol.
H0 : penambahan variabel X* tidak menambah kemampuan memprediksi berat badan atau dapat juga ditulis secara matematis dengan H0: β* = 0
Untuk melakukan uji F parsial, kita akan memerlukan data-data tentang nilai2 regresi serta jumlah kuadrat. Setelah menghitung dengan MINITAB kita akan mendapatkan nilai2 sebagai berikut: (lampiran hasil analisis dengan MINITAB dapat dilihat disini atau pada postingan sebelum ini.
Regresi jumlah kuadrat dari variabel tinggi badan terhadai berat badan {JK (X1)} = 588,92
Regresi jumlah kuadrat dari variabel tinggi badan dan umur terhadap berat badan {JK(X1,X2)} = 692,82
Regresi jumlah kuadrat dari variabel tinggi badan, umur dan umur kuadrat terhadap berat badan {JK ( X1.X2.X3)} =693,06
Dengan nilai-nilai tersebut di atas, kita dapat menghitung jumlah kuadratnya yaitu:
JK (X2IX1) = regressi JK (X1,X2) – regresi JK (X1) = 692,82 – 588,92 = 103,90
JK (X3IX1,X2) = regresi JK (X1,X2,X3) – regresi JK (X1,X2) = 693,06 – 692,82 = 0,24
Nilai-nilai tersebut kita masukkan ke dalam table rangkuman anava sebagai berikut:

Untuk mendapatkan nilai MS (mean square) dapat didapatkan dari SS : df. Adapun nilai F didapat dari MS : residual.
Dengan demikian, dari table di atas kita akan dapatkan

Dari nilai dapat disimpulkan bahwa variabel tinggi badan dapat meramalkan variabel berat badan. Hal ini karena nilai F hitung sebesar 19,67 lebih besar dari F table pada tingkat signifikansi 95% sebesar 5,12. Adapun setelah ditambahkan variabel umur, maka nilai F hitung sebesar 4,78 lebih kecil dari F table pada tingkat signifikansi 95% sebesar 5,12. Akan tetapi nilai ini masih tetap signifikan pada tingkat signifikansi 90%. Hal ini karena nilai F table pada tingkat signifikansi 90% sebesar 3,36. Dengan demikian, penambahan variabel umur setelah kita variabel tinggi badan secara signifikan dapat memprediksi berat badan pada tingkat signifikansi 90%.
Hal ini berbeda jika kita menambahkan variabel umur kuadrat. F hitung yang dihasilkan dari menambahkan variabel ini lebih kecil dari F table pada tingkat signifikansi 90% yaitu hanya sebesar 0,01. Dengan demikian, H0 diterima sehingga dapat disimpulkan bahwa variabel tinggi badan dan umur dapat memprediksi berat badan seseorang. Akan tetapi penambahan variabel umur kuadrat tidak berpengaruh secara signifikan dalam memprediksi berat badan.
Share







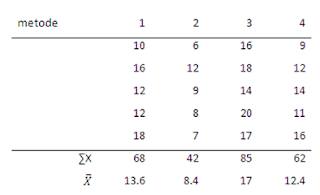
 berdasarkan table tersebut, kita dapat menyimpulkan bahwa H0 di tolak sehingga kita bisa mengatakan ada perbedaan yang signifikan dari keempat metode yang di pergunakan. Pertanyaan selanjutnya adalah metode manakah yang berbeda? Untuk menjawabnya kita memerlukan teknik tukey.
berdasarkan table tersebut, kita dapat menyimpulkan bahwa H0 di tolak sehingga kita bisa mengatakan ada perbedaan yang signifikan dari keempat metode yang di pergunakan. Pertanyaan selanjutnya adalah metode manakah yang berbeda? Untuk menjawabnya kita memerlukan teknik tukey.













