Setelah postingan sebelumnya menjelaskan tentang penyelesaian secara manual tentang analisis varian dua arah, maka pada postingan kali ini, akan di jelaskan bagaimana melakukan analisis tersebut dengan bantuan SPSS. Tidak seperti analisis manual yang rumit, analisis dengan SPSS sangatlah mudah.
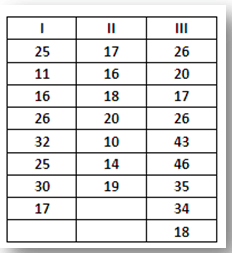
Untuk itu, kita akan gunakan data sebelumnya yang telah dipergunakan dalam perhitungan manual. Jika menggunakan SPSS, maka cara membuat data di SPSS adalah sebagai berikut:
Masukkan data kedalam SPSS sebagai berikut: